一、 项目成长中无法回避的“数据库之痛”
到目前为止,我们都依赖一个临时性的函数 create_db_and_tables() 来创建数据库表。这在项目启动初期很方便,但它有两个致命缺陷:
-
1. 它是一张单程票:这个函数只能从零开始创建表。如果表已经存在,它就无事可做。它完全不知道如何更新已经存在的表。 -
2. 它不安全:在生产环境中,赋予应用本身随意创建或删除表结构的能力,是极其危险的。数据库的结构变更应该是一个独立、严谨、可追溯的过程。
这就引出了一个非常真实的场景:我们的英雄模型 Hero,目前只有 name 和 alias 两个字段。但对于一个英雄来说,最重要的 能力(powers) 属性却被遗漏了!我们现在想给 heroes 表增加一个 powers 字段,该怎么办?
特别是,想象一下我们的项目已经上线,数据库里已经存储了成百上千条宝贵的英雄数据。我们总不能删库跑路吧?
“直接用数据库管理工具手动加一列不就行了?”
当然可以,但这就像在没有图纸和安全绳的情况下,给一栋正在使用的大楼做结构改造。万一改错了怎么办?万一不同环境(开发、测试、生产)的数据库改得不一致怎么办?万一几个月后,新来的同事根本不知道你做过这个手动修改怎么办?
我们需要的是一个专业的“数据库架构师”,它能:
-
• ✅ 版本化管理:像 Git 管理代码一样,管理数据库的每一次结构变更。 -
• ✅ 自动化生成:根据我们模型代码的变化,自动生成安全、可重复执行的变更脚本。 -
• ✅ 环境一致性:确保在任何环境下,数据库结构都能被精确地部署到指定版本。
今天,我们就来为项目引入这位“架构师”—— Alembic,一个基于 SQLAlchemy 的、业界标准的数据库迁移工具。为了能够实现首次迁移的效果,你可以先把数据库中的表清空,只建立一个空的数据库,首次迁移之后写入一些数据,来测试增加字段的功能。
二、初识 Alembic:奠定坚实的第一步
Alembic 是一个功能极其强大的工具。今天,我们将专注于它最核心、最常用的功能:初始化数据库和迭代更新表结构。
首先,让我们把这位“架构师”请进我们的项目。
uv add alembicuv 会像一个高效的管家,自动将 alembic 添加到 pyproject.toml 的依赖中,并完成安装。
安装完毕后,我们需要在项目中为 Alembic 创建一个工作空间。这个过程叫做“初始化”。
alembic init -t async alembic让我们把这个命令像剥洋葱一样层层解析:
-
• alembic init: 这是核心命令,意为“初始化 Alembic 环境”。 -
• -t async:t代表template(模板)。我们告诉 Alembic,请使用 异步(async) 模板来生成配置文件。因为我们的整个项目是基于asyncio和AsyncSession构建的,这一步至关重要。 -
• alembic: 命令的最后一个词,是我们要创建的目录名。你可以把它命名为migrations或任何你喜欢的名字,但alembic是最通用的约定。
执行完毕后,你的项目根目录下会多出一个 alembic 文件夹,里面装着 Alembic 的配置文件。
三、配置 env.py:让 Alembic 读懂我们的项目
在 alembic 文件夹中,alembic.ini 是主配置文件,但我们今天的主角是 env.py。这个文件是 Alembic 的“大脑”,我们在这里配置它,让它能智能地连接数据库、并找到我们定义的所有模型。
打开 alembic/env.py,我们将进行一场“外科手术式”的改造。
# alembic/env.py
import asyncio
from logging.config import fileConfig
from sqlalchemy.ext.asyncio import create_async_engine
from alembic import context
# ----------------- 我们改造的起点 -----------------
import os
import sys
from pathlib import Path
# 步骤1:将项目根目录加入 Python 的模块搜索路径
# 这确保了 Alembic 能找到我们 app 目录下的代码
project_root = Path(__file__).resolve().parent.parent
sys.path.insert(0, str(project_root))
# 步骤2:动态加载 .env 文件,让配置与环境同步
# 这让我们可以用类似 `ENVIRONMENT=prod alembic upgrade head` 的方式来操作不同数据库
ENV = os.getenv("ENVIRONMENT", "dev")
dotenv_file = project_root / f".env.{ENV}"
from dotenv import load_dotenv
load_dotenv(dotenv_file)
# 步骤3:导入我们的配置和模型定义的 Base
# 这是最关键的一步,让 Alembic 知道我们的数据库在哪,以及我们的模型长什么样
from app.core.config import Settings
from app.models import Base # 这会触发 app/models/__init__.py, 进而加载所有模型
# 实例化我们的配置
settings = Settings()
# ----------------- 我们改造的终点 -----------------
# 这是 Alembic 的配置对象,我们将把数据库 URL 注入进去
config = context.config
# ----------------- 注入数据库 URL -----------------
# 用我们从 settings 中读取的 URL 覆盖 alembic.ini 中的默认值
config.set_main_option("sqlalchemy.url", settings.DB.DATABASE_URL)
# ----------------------------------------------------
# 从配置文件中解释日志配置。
if config.config_file_name is not None:
fileConfig(config.config_file_name)
# ----------------- 设置目标元数据 -----------------
# 这是 Alembic 进行比对的“最终蓝图”
target_metadata = Base.metadata
# -------------------------------------------------
def run_migrations_offline() -> None:
# ...(省略,保持默认)...
async def run_migrations_online() -> None:
# ...(省略,保持默认)...
if context.is_offline_mode():
run_migrations_offline()
else:
asyncio.run(run_migrations_online())配置精讲:
-
1. 路径设置 ( sys.path.insert): 我们告诉 Python:“在查找模块时,请把我们项目的根目录也看一看。”这样,当env.py想from app.core.config import Settings时,它才能找得到app这个包。 -
2. 动态配置 ( load_dotenv): 我们复用了项目中的多环境配置逻辑。这意味着你可以通过设置环境变量来控制 Alembic 操作的是开发数据库还是生产数据库,极其灵活。 -
3. 模型元数据 ( target_metadata):target_metadata = Base.metadata这行代码是重中之重。它把我们所有 SQLAlchemy 模型(继承自Base)的结构信息集合——metadata——交给了 Alembic。Alembic 会将这份“代码里的最终蓝图”与“数据库里的实际建筑”进行比对,从而发现差异。
💡 一个关键的最佳实践
Alembic 如何知道我们项目里有哪些模型?答案就在
app/models/__init__.py。# app/models/__init__.py
from .base import Base
from .users import User
from .heroes import Hero
__all__ = ["Base", "User", "Hero"]当
env.py执行from app.models import Base时,这个__init__.py文件会被执行,它像一个“模型登记员”,将我们所有的模型都加载了进来,确保Base.metadata包含了User和Hero的所有信息。请务必确保你所有的新模型都在这里被导入!
四、首次迁移:将蓝图变为现实
配置完成!现在,让我们来执行第一次迁移,将我们定义的 User 和 Hero 模型创建为数据库中的表。
第一步:生成迁移脚本
uv run alembic revision --autogenerate -m "Initial migration"-
• revision: 创建一个新的迁移版本文件。 -
• --autogenerate: 这是 Alembic 的魔法核心! 它会自动检测target_metadata和数据库之间的差异,并生成相应的 Python 迁移代码。 -
• -m "...":message的缩写,为这次迁移写一句像 Git commit 一样的说明,方便日后回顾。
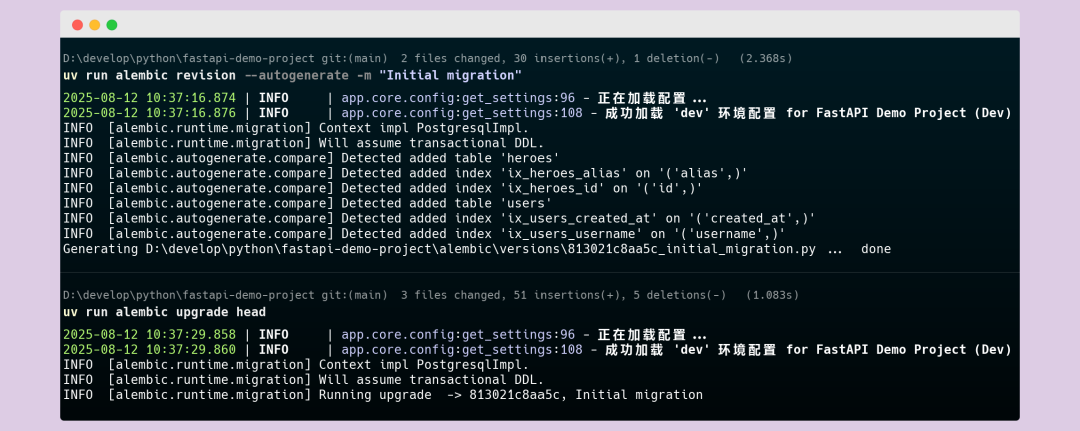
执行后,alembic/versions 目录下会生成一个新的 Python 文件。它里面定义了 upgrade()(升级)和 downgrade()(降级)两个函数,清晰地描述了如何创建 users 和 heroes 表。
第二步:应用迁移
uv run alembic upgrade head-
• upgrade: 执行升级操作。 -
• head: 表示升级到最新的版本。
这条命令会运行刚才生成的迁移脚本中的 upgrade() 函数。
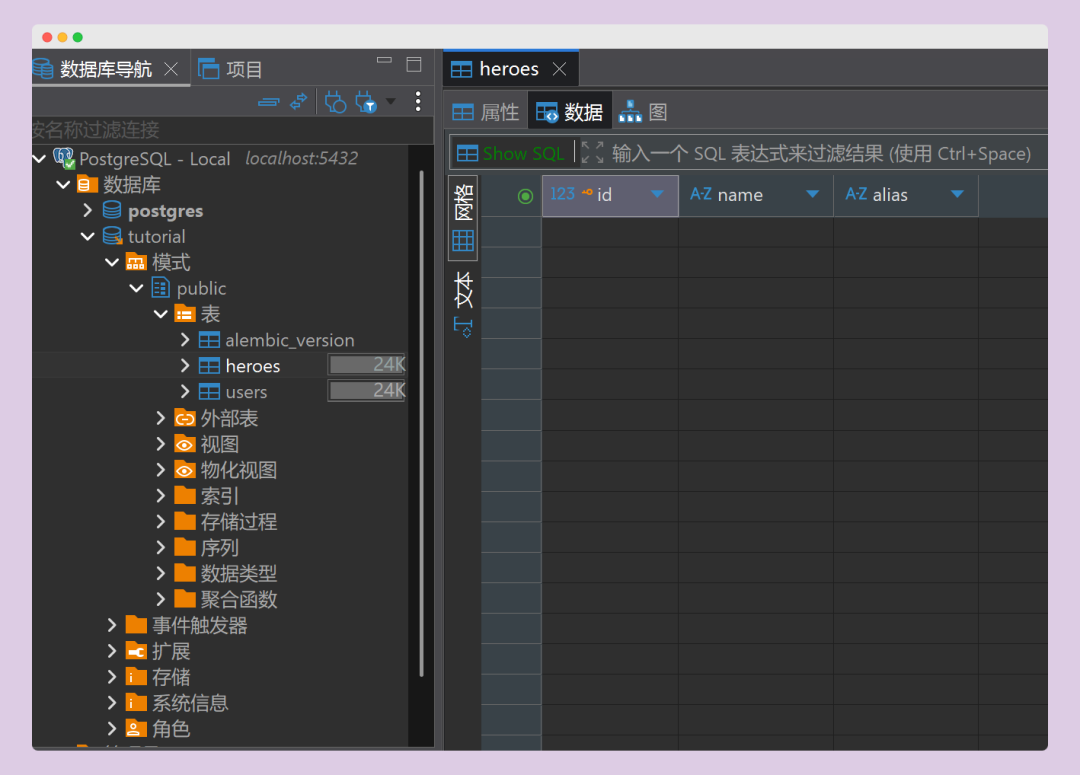
执行成功后,你会发现数据库中多了三张表:users、heroes,还有一个陌生的 alembic_version 表。
🛡️
alembic_version表:数据库的“安全书签”这个表是 Alembic 的核心账本。它里面只存一行数据,记录了当前数据库已经应用到的最新迁移版本的 ID。每次你运行
upgrade或downgrade,Alembic 都会先查这个表,来确定自己应该从哪个版本开始工作,并将最终的版本号记录下来。这保证了迁移操作绝不会重复执行,安全可靠。
五、迭代更新:为英雄赋予超能力
现在,让我们来解决最初的问题:为英雄增加 powers 字段。
第一步:修改模型
我们首先更新代码,在 Hero 模型中加入 powers 字段。
# app/models/heroes.py
from sqlalchemy import String, Integer, Text
from sqlalchemy.orm import Mapped, mapped_column
from app.models.base import Base
class Hero(Base):
__tablename__ = "heroes"
id: Mapped[int] = mapped_column(Integer, primary_key=True, index=True)
name: Mapped[str] = mapped_column(String(100), nullable=False)
alias: Mapped[str] = mapped_column(String(100), unique=True, nullable=False, index=True)
# 💡 新增一个 powers 字段,注意它必须是可选的!
powers: Mapped[str | None] = mapped_column(Text, nullable=True) # 使用Text可以存储更长的文本
def __repr__(self) -> str:
return f"{self.id!r}, name={self.name!r}, alias={self.alias!r})>"⚠️ 注意!一个至关重要的细节!
新增的powers字段我们设置了nullable=True。这是因为我们的数据库里可能已经存在英雄数据了,对于这些“老”数据,powers字段是空的。如果设置为nullable=False(不许为空),数据库会报错。记住:为已有数据的表增加新字段时,通常都要允许其为空。
第二步:再次生成并应用迁移
我们重复之前的流程,但使用新的描述信息。
uv run alembic revision --autogenerate -m "Add powers column to heroes table"
uv run alembic upgrade head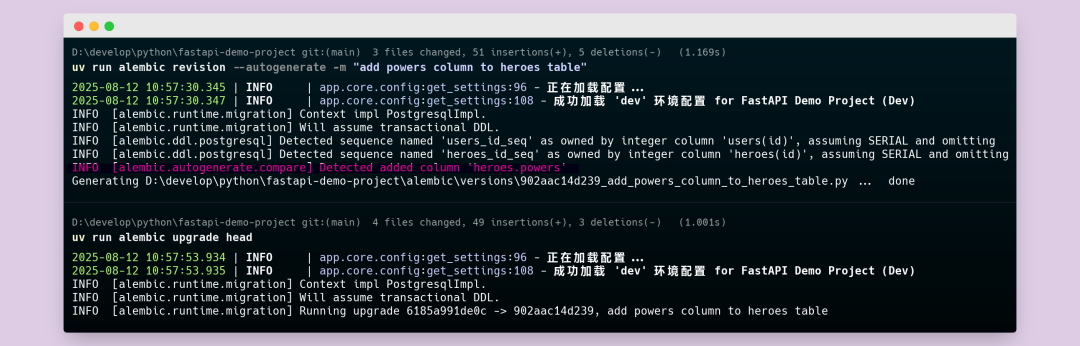
你会看到,Alembic 聪明地检测到了变化:“Detected added column ‘heroes.powers’”。它只生成了增加这一列的代码。
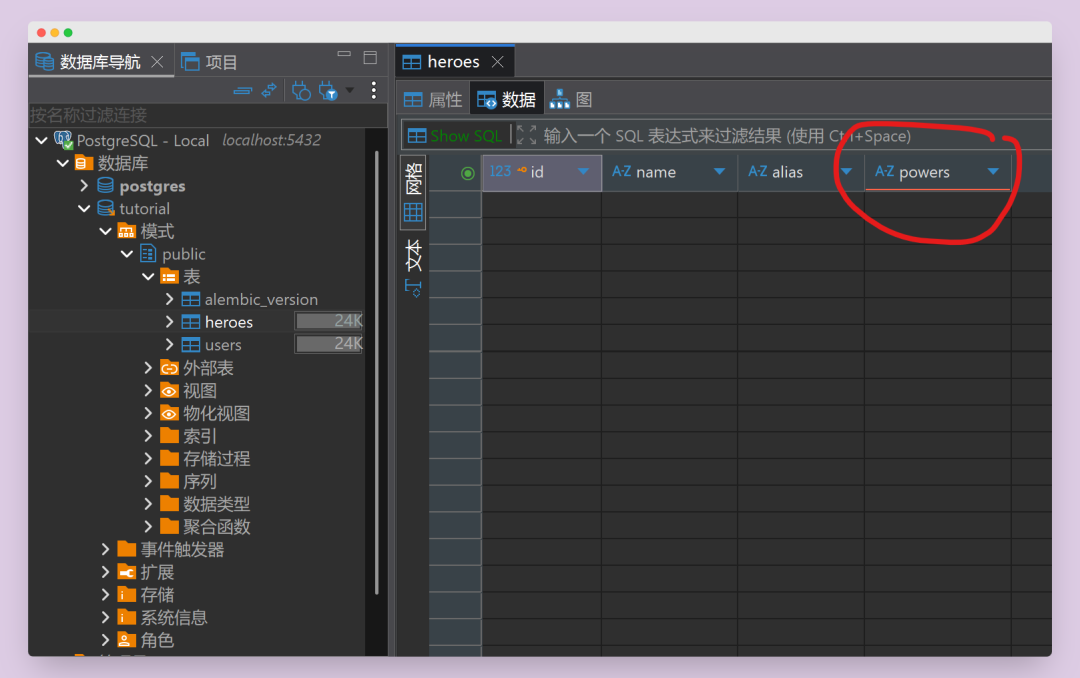
现在再看 heroes 表,powers 字段已经稳稳地躺在那里了!
六、时光倒流:万一后悔了怎么办?
如果你发现这次升级有问题,想撤销它怎么办?Alembic 这台“时光机”随时待命。
uv run alembic downgrade -1downgrade -1 意味着“回退一个版本”。执行它,Alembic 会找到上一个版本的迁移脚本,并执行里面的 downgrade() 函数,在这里就是删除 powers 字段,同时更新 alembic_version 表。就像这次变更从未发生过一样!
-
• 如果想一次回退 N 个版本,用 -N,例如-2。 -
• 也可以直接指定目标 revision 号: alembic downgrade。
总结与展望
恭喜你!今天我们一起为项目装备了最专业的数据库管理工具 Alembic。我们不仅学会了:
-
1. 如何初始化和配置 Alembic,使其与我们的异步项目无缝集成。 -
2. 如何执行首次迁移,从零开始安全地创建数据库表。 -
3. 如何进行迭代迁移,在项目发展中优雅地更新表结构。 -
4. 如何使用 downgrade,作为我们最后的“后悔药”。
这套流程,让你彻底告别了手动修改数据库的刀耕火种时代,进入了自动化、版本化的现代开发模式。
当然,Alembic 的能力远不止于此。对于更复杂的场景,比如需要进行数据回填(给老数据的 powers 列填充默认值)、处理复杂的外键约束变更等,就需要我们手动去编写迁移脚本的逻辑。但掌握了今天的内容,你已经拥有了解决 80% 数据库迁移问题的能力。
如果你需要学习 Alembic 的进阶内容,请查看他们的官方文档:
https://alembic.sqlalchemy.org/en/latest/